



Artificiell intelligens (AI) fortsätter att vara den beräkningskategori som dammsuger marknaden på tillgänglig avancerad hårdvara. Förutom krav på skyhög beräkningskraft krävs enorma mängder snabbt minne, vilket resulterat i att den tidigare perifera och nischade tekniken High-Bandwidth Memory (HBM) blivit nästa tillväxtområde för Samsung, SK Hynix och Micron.
Tidigare under året gick TSMC och SK Hynix ut med att de skulle samarbeta om nästa generations minnesteknik HBM4. Nu klargörs vad TSMC:s roll spelar i detta och likt vad Semi14 spekulerade i ska de lösa de högre krav som ställs med HBM4 gällande kapsling och signalintegritet av färdiga HBM-lösningar. Detta är någonting SK Hynix och dess rivaler fram till dagens HBM3E klarat av att leverera på egen hand.
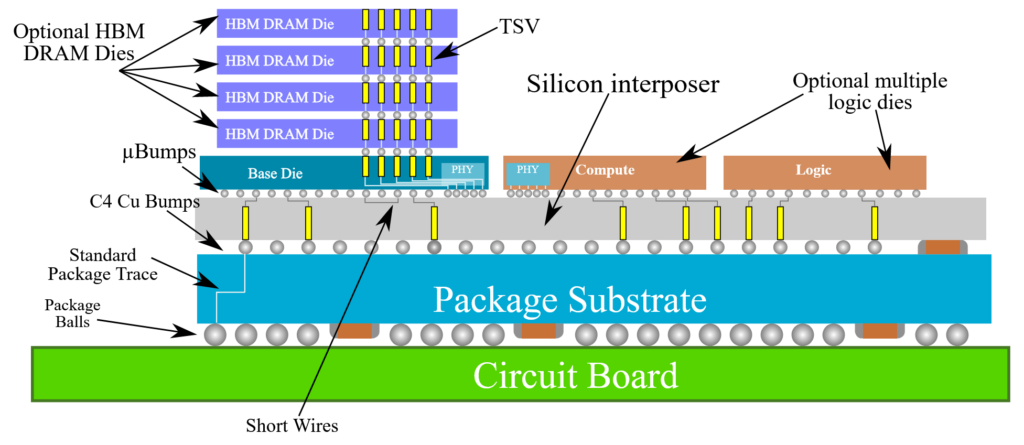
TSMC har tagit fram två olika base dies, vilken är den krets som de många minneskretsarna staplas på och som ansluter den till en helhetslösning där bland annat beräkningskretsen ingår. För ändamålet finns två tillverkningstekniker för olika prisklasser – den ena N12FFC+, som är en skräddarsydd variant av bolagets FinFET-process om 16 nanometer, och N5, som är den än idag högaktuella 5-nanometersteknik som används av praktiskt taget alla TSMC-kunder i spjutspetsen. Undantaget från regeln är Apple som gått över till nästa nod 3 nanometer.
Den mer kostnadseffektiva tekniken N12FFC+ ska användas för base dies där 12 (12-Hi) och 16 (16-Hi) kretsar om 32 Gb (4 GB) vardera staplas ovanpå varandra, för att skapa enskilda kapslar om hela 48 respektive 64 GB. Denna lösning ska räcka för att möta specifikationerna för HBM4 och är framförallt tänkt att användas på samma vis som dagens HBM-tekniker, vilka placeras jämte en beräkningskrets på ett kiselsubstrat.
| N12FCC+ | N5 | |
| Area | 1x | 0,39x |
| Frekvens vid given strömförbrukning | 1x | 1,55x |
| Strömförbrukning vid given frekvens | 1x | 0,35x |
Med N5 består hur många minneskretsar som kan staplas ovanpå varandra. De uppenbara skillnaderna jämfört med N12FCC+ handlar istället om fördelar gällande kretsarea, 55 procent högre klockfrekvens vid samma strömförbrukning alternativt 65 procent lägre strömförbrukning vid samma klockfrekvens. Eller någonstans däremellan för de två senare aspekterna.
Användningen av N5 för nästa generations HBM handlar dock om mer än högre prestanda. Att en base die på tekniken kan husera mer än dubbla mängden transistorer gör att flera funktioner i en färdig HBM4-kapsel kan integreras och att högre interconnect pitch för fler anslutningspunkter kan rymmas på undersidan. Det öppnar för nya möjligheter inom tillverkning, där ett exempel är direct bonding där HBM-kapslar kan staplas direkt ovanpå en beräkningskrets. Detta medför stora utmaningar gällande värmeavledning, men även fördelar sett till prestanda då minnet i praktiken kan användas som ett traditionellt cacheminne.
Vilken prestanda som är att vänta med HBM4 är ännu inte känt, men det ligger i korten att det handlar om mer än en dubblering jämfört med HBM3E. En av de stora förändringarna som sker är att bussbredden per kapsel dubbleras till 2 048 bitar, vilket innebär en dubblering jämfört med HBM3E vid samma klockfrekvens (MT/s). Detta kräver både en ökning i interconnect pitch, vilket N12FCC+ och N5 erbjuder, men även på aktörer likt Nvidia och AMD att göra bättre minneskontroller. Utöver avancerade base dies behöver även TSMC förbättra sin paketeringsteknik Chip-on-Wafer-on-Substrate (CoWoS), något de samarbetar med EDA-partner likt Cadence, Synopsys och Ansys för att möjliggöra.
Även om allt fler detaljer om HBM4 publiceras ligger tekniken ett par år bort från att lanseras. Den idag rådande färdplanen är att minnestekniken går in i produktion under 2026 och att färdiga beräkningslösningar lanseras först 2027.

