



Arkitekturen Ada Lovelace
Grunden för den nya Geforce RTX 4000-serien är som tidigare nämnt Ada Lovelace och jätteklivet från Samsungs 8 nanometer till TSMC:s 4 nanometer ökar transistorbudgeten rejält. På samma kretsyta ryms närmast tredubblas antalet transistorer, vilket är en ökning utan motstycke från Nvidias sida. I praktiken bör det innebära en betydande ökning i kapacitet och prestanda.
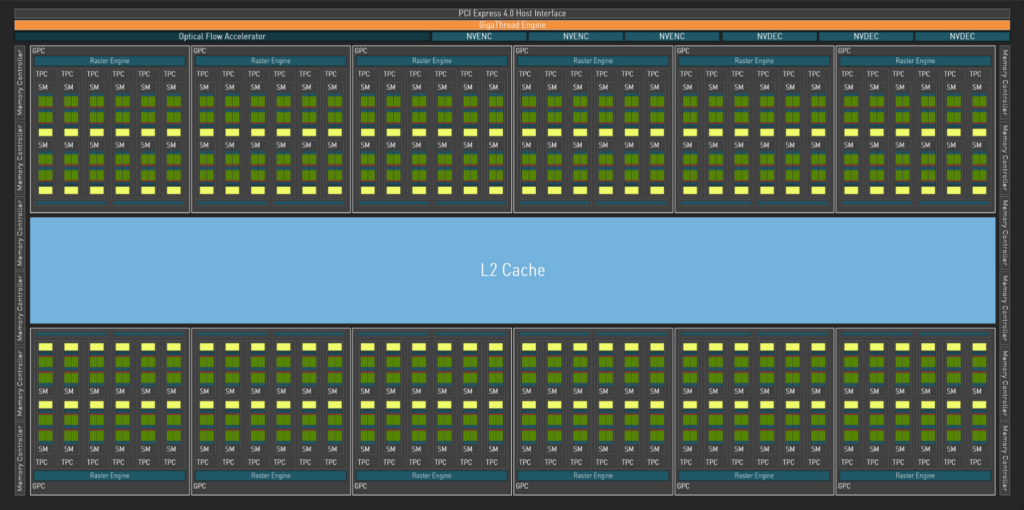
Hjärtat i flaggskeppet Geforce RTX 4090 är grafikkretsen AD102, som i grova penseldrag levererar mer av allt jämfört med GA102 i föregångaren RTX 3090 Ti. Arkitekturens uppbyggnad ser vid första anblick ut som Ampere i ett uppskalat utförande med fler beräkningsenheter, men de tillsynes liknande byggstenarna har tack vare den utökade transistorbudgeten förbättrats.

När vi blickar på grafikkretsen i sin helhet består den av 12 Graphics Processing Cluster (GPC). Varje GPC huserar 12 rasterenheter (ROP) som beräknar pixelinformation för de trianglar varje GPC tilldelas. Detta är en förändring mot Ampere, där varje GPC huserade 16 rasterenheter, men det vägs upp av det faktum att AD102 har 12 GPC-enheter istället för endast 7 hos GA102. Totalt handlar det om 192 respektive 112 rasterenheter, en ökning om drygt 71 procent.
Varje GPC innehåller därtill 6 stycken Texture Processing Cluster (TPC), som i sin tur huserar en Polymorph Engine. Denna hanterar beräkningar av geometri, vilket bland annat innebär att 3D-objekt och ytor delas upp i mindre delar, även känt som tesselering. Vid sidan om denna huserar varje TPC två stycken Streaming Multiprocessors (SM), själva beräkningsenheten i grafikkretsen.
Det är i SM-enheten vi finner Nvidias beräkningsenheter för heltal (integer, INT32) och flyttal (floating-point, FP32), något Nvidia väljer att kalla CUDA-kärnor och i varje SM-enhet finns totalt 128 stycken. Likt Ampere väljer Nvidia att prioritera beräkningar i flyttal och samtliga 128 ”CUDA-kärnor” kan utföra FP32-beräkningar, medan endast hälften (64 stycken) kan utföra INT32-beräkningar. Med andra ord – en SM-enhet kan utföra upp till 128 stycken FP32-operationer per klockcykel eller 64 stycken FP32 och 64 stycken INT32. Varje SM-enhet har 128 KB L1-cacheminne, upp från tidigare 96 KB.
Sedan lanseringen av arkitekturen ”Turing” i Geforce RTX 2000-serien satsar Nvidia stort på såväl maskininlärning som ray tracing. I takt med att det blir svårare och dyrare att krympa transistorer är vägen framåt mer specialiserade funktioner i kombination med mjukvara. Här stavar Nvidia framtiden Deep Learning Super Sampling (DLSS), en kombinerad kantutjämnings- och uppskalningsteknik, med vilken tanken är att genom maskininlärning kunna skala upp en lägre upplöst bild till en högre upplöst utan att göra avkall på kvaliteten.
SM-enheterna i AD102

För ändamålet har varje SM-enhet en Tensor-kärna för maskininlärning och en RT-kärna för ray tracing i realtid. Här handlar det inte om samma kärnor som i Ampere utan kapaciteten är dubblerad på båda, något som kommer väl till pass när Nvidia fortsätter öka prestandan genom maskininlärning och att göra användningen av ray tracing till standard för ljussättning. Vid sidan om dubblerad kapacitet klarar Tensor-kärnorna numera av att utföra beräkningar i lägre precision om FP8, vilket i ett optimalt scenario ger dubblerad prestanda jämfört med tidigare FP16-beräkningar.
Samtidigt som RT-kärnornas kapacitet fördubblats har de fått några nya funktioner. Opacity Micro-Map (OMM) möjliggör för betydligt snabbare ray tracing på transparenta ytor. Vidare optimerar Displaced Micro-Mesh (DMM) generering av strukturen för Bounding Volume Hierarchy (BVH), vilket är det sätt Nvidia valt att använda för att utföra ray tracing-beräkningar. Att hitta den triangel ljusstrålen (ray tracing) ska studsa mot är svårt och tar tid, men underlättas av BVH där ett tredimensionellt objekt delas in i olika lådor med resultatet att urvalet av trianglar att träffa blir färre.
Förbättringar i ray tracing



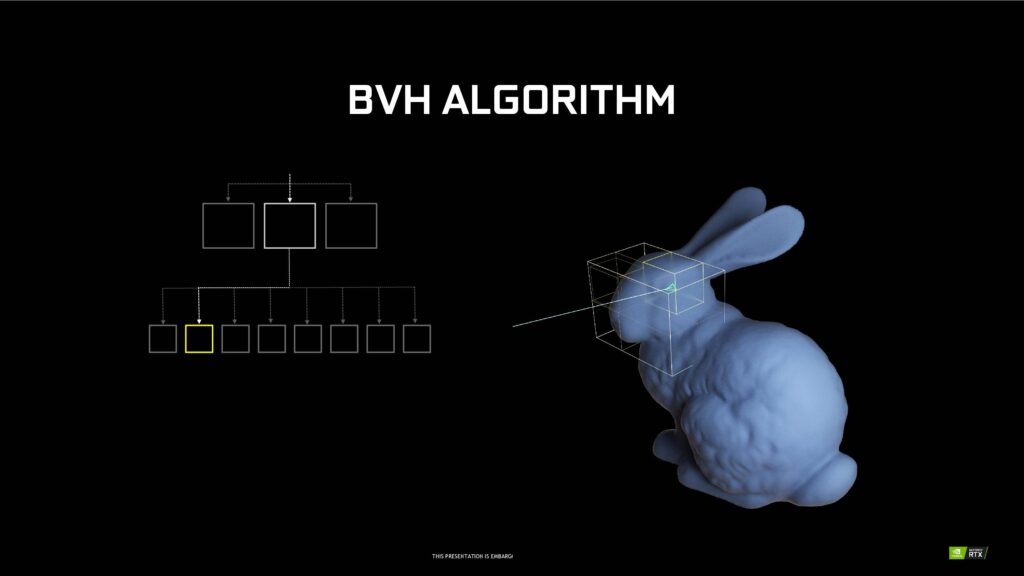
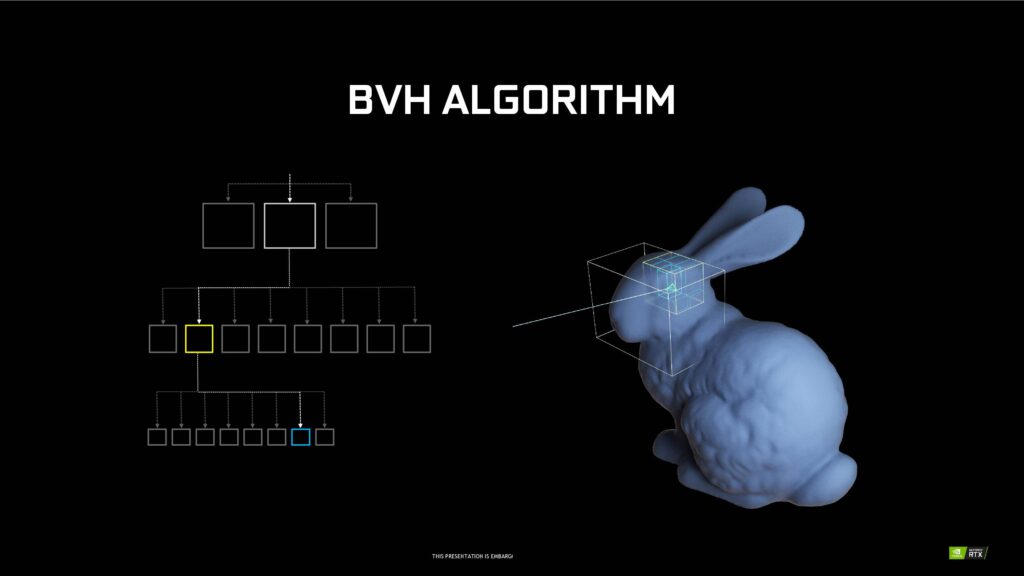
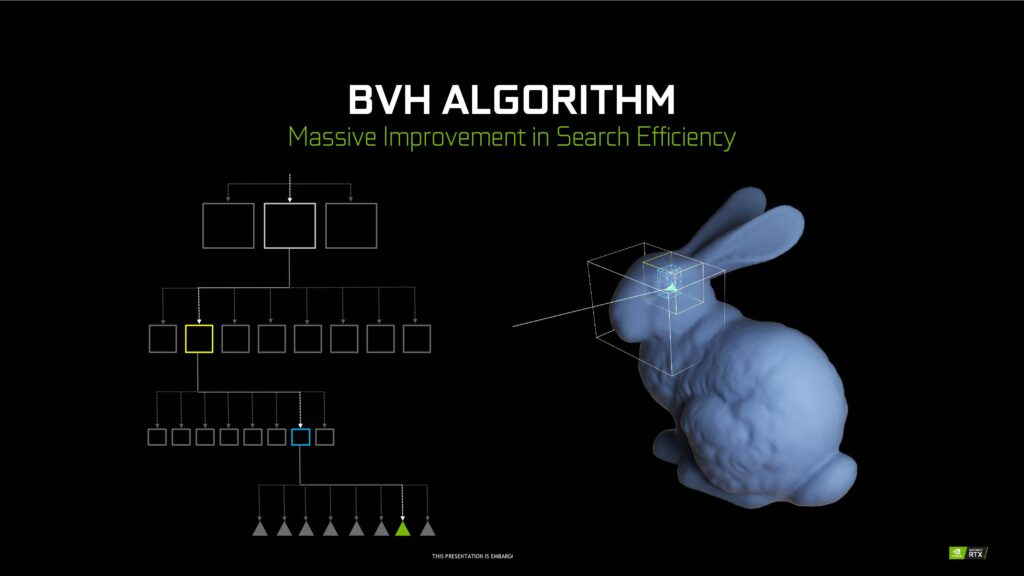
Enligt Nvidia medför detta enorma förbättringar vid ray tracing – upp till 10 gånger snabbare generering av BVH-strukturer med blott 5 procent minnesanvändning jämfört med Ampere. Värt att notera är att detta inte är någon gratis lunch som kommer fungera från dag ett, utan att möjliggöra detta kräver stöd i mjukvara och optimering från utvecklare.
Blickar vi ut från SM- och GPC-enheterna och åter tar en närmare titt på helheten har Nvidia skruvat upp mängden L2-cacheminne betydligt. Från 12 MB hos gräddan av Ampere, GA102, till 72 MB hos AD102. Den som har koll på AMD:s grafikkort vet att bolaget satsat stort på sitt så kallade Infinity Cache, ett marknadsföringsnamn för deras cacheminne, där toppkretsen har 128 MB.
Ett stort cacheminne är ett relativt enkelt sätt att öka energieffektiviteten, då mer data kan lagras närmare själva beräkningsenheterna. Kostnaden att komma åt data räknat i latens och energiförbrukning är betydligt lägre i ett cacheminne jämfört med att behöva hämta det från GDDR6-/GDDR6X-minnet. I AMD:s fall var det också ett designbeslut för att kunna använda en snävare minnesbuss, där toppkretsen Navi 21 hade en bussbredd om blott 256 bitar.
Att Nvidia sexdubblar sitt cacheminne sker av liknande skäl som ovan. Toppkretsen AD102 har likt föregångaren GA102 en bussbredd på 384 bitar och då inget stort hänt på minnesfronten betyder det att den teoretiska minnesbandbredden blir densamma. Ett större cacheminne ger vid sidan om förbättrad energieffektivitet således även ett prestandalyft som annars inte hade varit möjligt.
Sett till minnesstödet stannar Ada Lovelace kvar vid GDDR6 och GDDR6X, vilka är de bästa som finns tillgängliga idag vid sidan om High-Bandwidth Memory (HBM) som visat sig vara för dyrt att använda i konsumentled. Minnesstandarderna finns i effektiva klockfrekvenser om väl över 20 000 MHz (20 Gbps), men med Ada Lovelace väljer Nvidia att inte ta ut alltför mycket på svängarna med toppmodellen. Mer om det när det är dags att titta på specifikationerna.
Att utveckla en ny arkitektur med tillhörande kretsar är alltid en avvägning, där olika funktioner och kapacitet på dessa vägs mot varandra. Med Ada Lovelace är det tydligt var Nvidia valt att lägga sina prioriteringar. De traditionella beräkningsenheterna, CUDA-kärnorna, har knappt genomgått några förändringar och har endast ökat med drygt 71 procent till antalet. Detta trots att transistorbudgeten nästan tredubblats jämfört mot förra generationen. Antalet Tensor- och RT-kärnor ökar lika mycket, men kapaciteten för varje kärna är även dubblerad samtidigt som de fått nya funktioner.
Krutet har således lagts på att markant öka kapaciteten för maskininlärning och ray tracing. Bland entusiaster råder här delade meningar kring sådana nymodigheter och om det inte vore bättre att helt enkelt fortsätta ”fuska” med traditionell rastrering. Nvidia, snart även AMD, och nykomlingen Intel gör uppenbarligen en annan bedömning. Framtiden är att avancerade uppskalningstekniker likt DLSS och ljussättning genom ray tracing kommer bli vanligare.
För att summera AD102, gräddan av Ada Lovelace för konsumenter, innehåller den 18 432 CUDA-kärnor, 144 RT-kärnor, 576 Tensor-kärnor, 576 texturenheter, 192 rasterenheter, 72 MB L2-cacheminne och en 384-bitars minnesbuss. Detta att jämföra mot Ampere-baserade GA102 med sina 10 752 CUDA-kärnor, 84 RT-kärnor, 336 Tensor-kärnor, 336 texturenheter, 112 rasterenheter, 12 MB L2-cacheminne och 384-bitars minnesbuss.
En brasklapp med AD102 är att den inte släpps i sitt fullfjädrade utförande. Likt när Nvidia lanserade arkitekturen Ampere och RTX 3090 introduceras toppkretsen i nedskalat utförande. Det är sannolikt en kombination av yield, att andelen fungerande kretsar med 76 miljarder transistorer är för få till antalet, men också proaktiv segmentering för att kunna lansera ett nytt grafikkort längre fram i tiden. Likt hur Nvidia gjorde med RTX 3090 Ti som till slut levererade all kapacitet som fanns att hämta hos GA102.

Grafikkretsen AD102 tar först plats i Geforce RTX 4090 och 16 av 144 SM-enheter är inaktiverade, motsvarande 12,5 procent av alla beräkningsenheter. Resultatet är 16 384 CUDA-kärnor, 128 RT-kärnor, 512 Tensor-kärnor, 512 texturenheter och 176 rasterenheter, medan cacheminnet på 72 MB och den 384 bitar breda minnesbussen är lämnad orörd.
Sist och definitivt inte minst är att Nvidia gått över till en ny tillverkningsteknik. Förutom att kunna packa transistorer tätare är transistorerna högre presterande, vilket i sammanhanget är att de kan nå högre klockfrekvenser. I fallet AD102 och Geforce RTX 4090 kliver boost-frekvensen för grafikkretsen upp med hela 660 MHz – från 1 860 MHz hos RTX 3090 Ti till 2 520 MHz. Det i sig är en ökning om 35,5 procent, vilket ska appliceras på förbättringarna ovan. Resultatet är ett grafikkort med mer än dubblerad teoretisk beräkningskraft jämfört mot dess föregångare. Tidiga indikationer talar även för att det är möjligt att nå klockfrekvenser om cirka 3 000 MHz.
Det finns mycket mer att beröra när det kommer till nya funktioner och inte minst på mjukvarusidan. Med Ada Lovelace slår Nvidia på stora trumman för DLSS 3.0 och att det är möjligt att i vissa fall fyrdubbla prestandan jämfört med Ampere.

