



Arkitekturen Zen 4
För att förstå AMD:s iterationer av arkitekturer är en snabb tillbakablick av nytta. Med Zen (1) introducerades en ny arkitektur, Zen+, som tillverkades på en optimerad 14-nanometersteknik hos Globalfoundries kallad 12 nanometer och fick tightare cache-latenser samt högre klockfrekvenser. Nästa steg blev Zen 2 där AMD gjorde faktiska ingrepp i arkitekturen, gick över till TSMC för tillverkning på 7 nanometer och införde en ny chiplet-design där flera kretsar utgjorde en färdig produkt. Med Zen 3 blev ingreppen större, men tillverkningstekniken förblev densamma.
Arkitekturen Zen 4 kan i denna kontext likställas med skiftet till Zen 2 där ny tillverkningsteknik är den stora nyheten. Det handlar dessutom om ännu en iteration av Zen med förbättringar för att öka såväl antalet instruktioner per klockcykel (IPC), bland annat genom nya instruktioner och optimeringar, för att tillsammans med den nya tillverkningstekniken möjliggöra för högre klockfrekvenser.
Tillverkningstekniken i fråga är TSMC:s 5 nanometer och här talar AMD om ett nära samarbete för att nå sina prestandamål, vilka i halvledarsammanhang primärt mäts enligt tre parametrar – prestanda (klockfrekvens, performance), energieffektivitet (power) och transistortäthet (area) – förkortat PPA. Sett till prestandamålen tar AMD med sin nya toppmodellen Ryzen 9 7950X ett rejält skutt upp till 5,7 GHz, hela 800 MHz över föregångaren 9 5950X.
Det är inte enbart kretsen för själva processorkärnorna, som kallas för Core Complex Die (CCD), som gått över till en mer avancerad tillverkningsteknik. Dessa ansluts till en ny Input Output Die (IOD), som huserar alltifrån den integrerade grafikdelen till PCI Express och minneskontroller för DDR5-minne, vilken tillverkas på TSMC:s 6-nanometersteknik. Tidigare IOD-kretsar har tillverkats på 12/14 nanometer hos Globalfoundries.
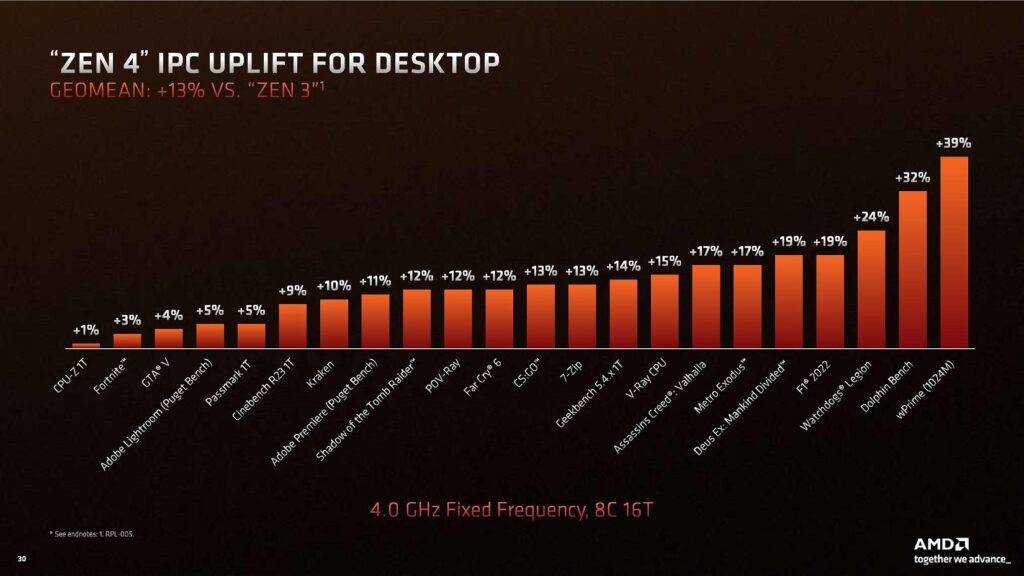
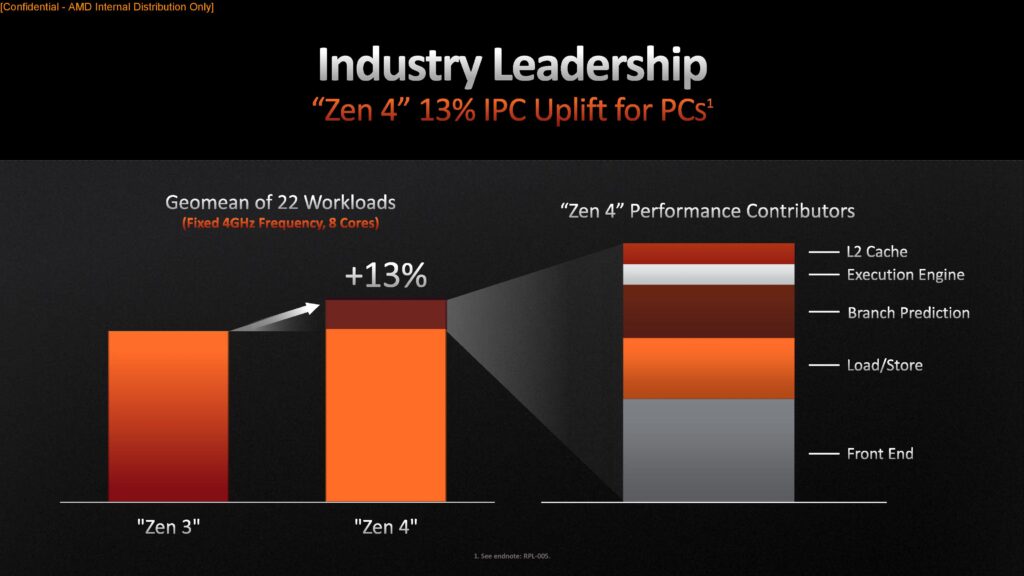
Ökningen i maximal klockfrekvens om dryga 16 procent flankeras av en IPC-ökning om 13 procent, något AMD menar är en bra bit över det egna målet om 8 procent. Det handlar som brukligt inte om en siffra som kan appliceras över alla applikationer, utan prestandaökningen beror helt på vilka delar av processorkärnan som används. För att få fram sina 13 procent använder AMD ett snitt över 22 olika scenarion. Tillsammans med de ökade klockfrekvenserna talar AMD om ett snittvärde på 29 procent i enkeltrådad prestanda, då när den nya och forna toppmodellen jämförs.

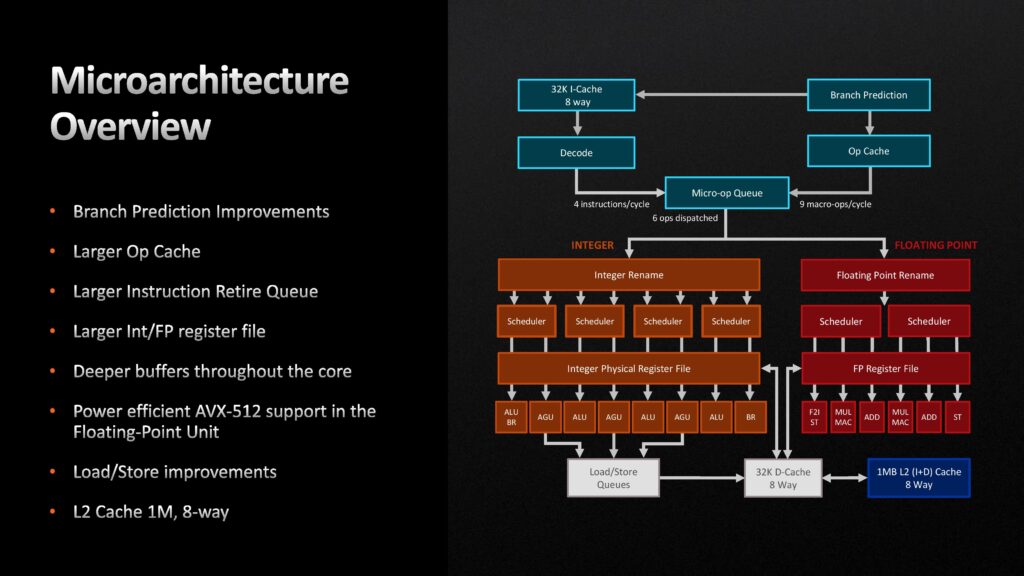
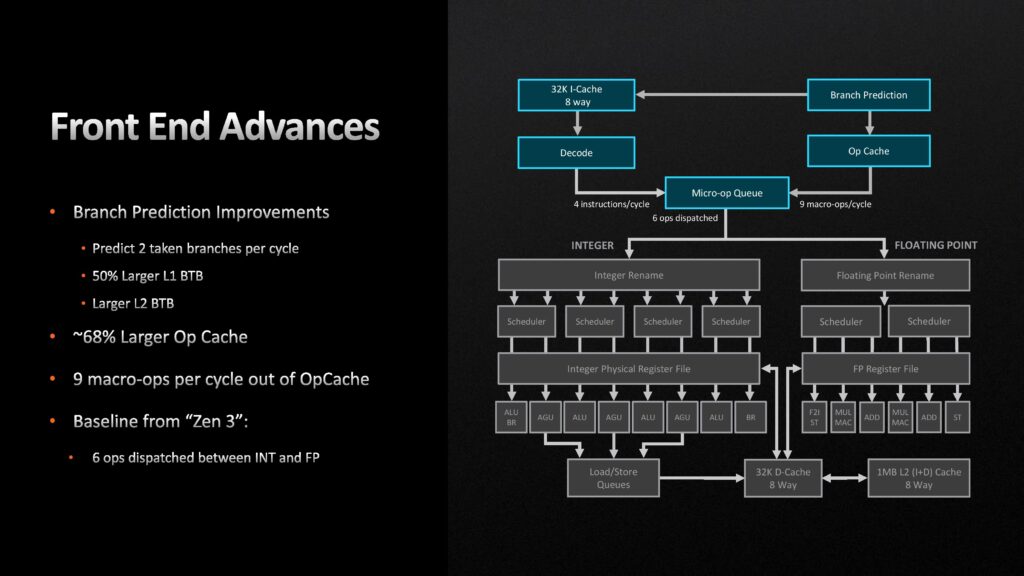

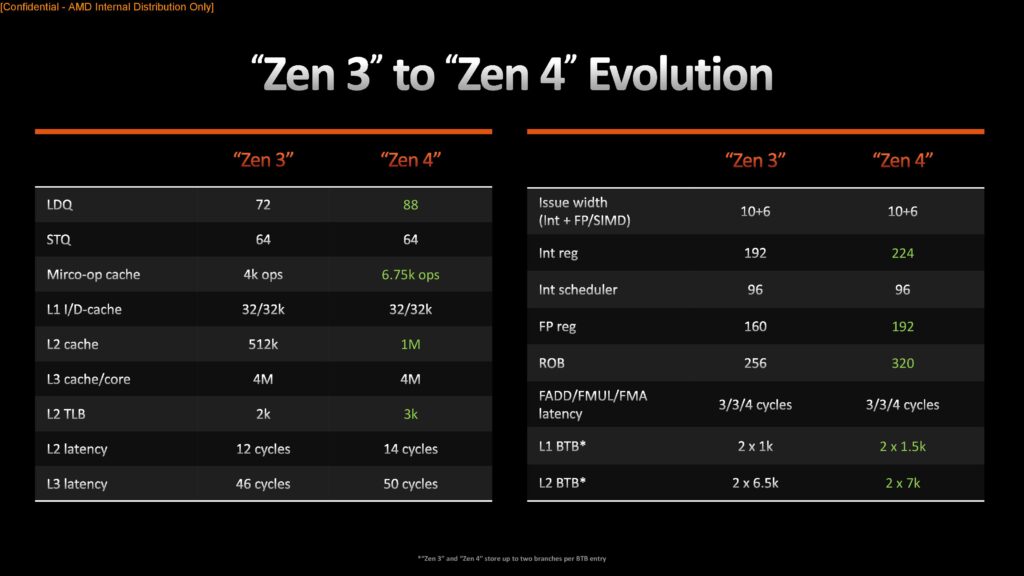
Gällande förbättringarna som skett tillskrivs den enskilt största ökningen en ny front-end med tillhörande branch prediction-enhet, där den senares jobb är att ”gissa” nästa instruktion för att öka prestandan. Jämfört med Zen 3 kan Zen 4 utföra två branch predictions per klockcykel, L1- och L2-cacheminnet har 50 procent större Branch Target Buffers, det lilla Op Cache-minnet är 68 procent större och och kan utföra 9 operationer per klockcykel.
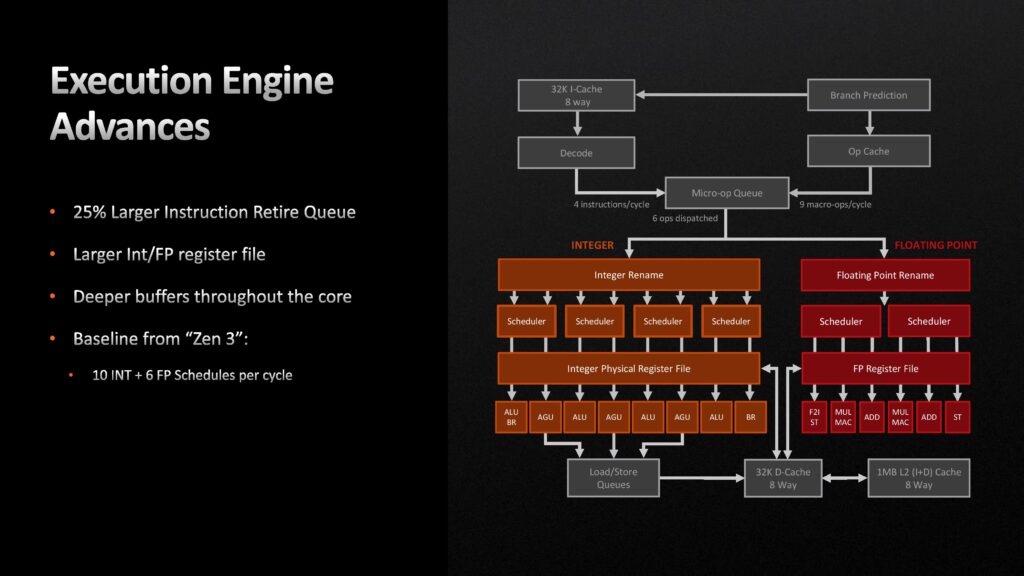
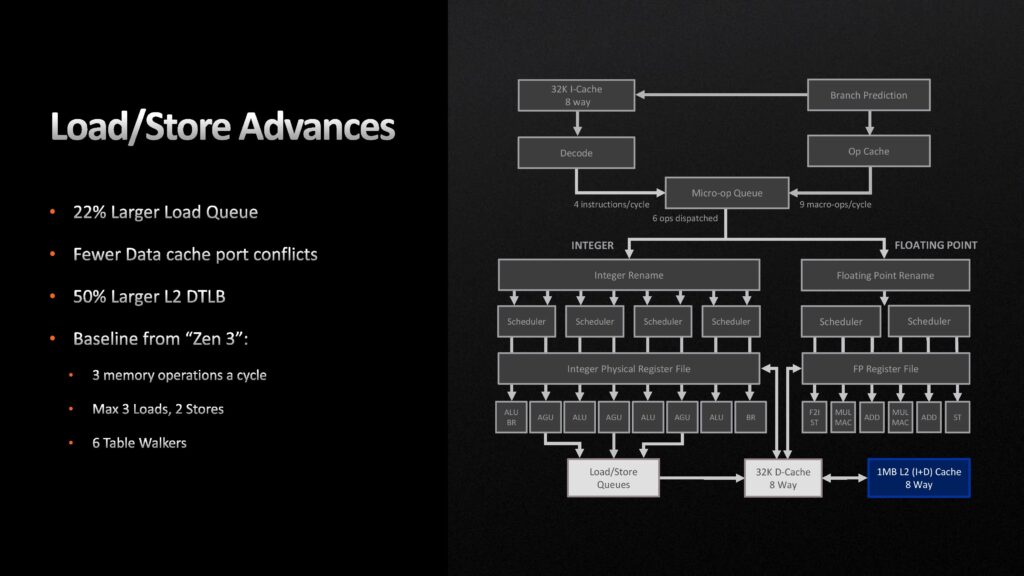
Den tredje stora förbättringen ligger i Load/Store-kön, där registerfiler för både heltal och flyttal placerar schemalagda poster. Denna växer med 22 procent, och L2-cacheminnets Data Translation Lookaside Buffer med 50 procent. På tal om L2-cacheminnet har det sedan Zen (1) varit 512 KB stort, men med Zen 4 dubbleras det till 1 MB. En annan effekt av det större cacheminnet vid sidan om bättre prestanda är att det ökar energieffektiviteten, när mer data ryms däri och kärnorna inte lika ofta behöver läsa från DDR5-primärminnet.
Intressant är att exekveringsenheterna, Execution Engine, som utför de faktiska beräkningarna står för en relativt liten del av IPC-ökningen. Detta trots 25 procent större, registerfilen för heltal växer från 192 till 224 poster, för flyttal från 160 till 192 poster och djupare buffers. Sammantaget är det främst att arkitekturen mer effektivt kan hantera instruktioner och mata exekveringsenheterna som står bakom de stora förbättringarna.
AMD:s teknik för turbofrekvenser är fortfarande Precision Boost 2 som introducerades redan med Ryzen 2000-serien. Det är en teknik där kärnornas alla klockfrekvenser justeras dynamiskt efter belastning, hur många kärnor som belastas och vilka av dessa som är bäst lämpade för högsta möjliga turbofrekvens. Det sista avser exemplarvariationer, det så kallade kisellotteriet, som är ett faktum med alla halvledare.
Alla transistorer är inte lika vid tillverkning utan många faktorer påverkar yield, det vill säga andelen fungerande kretsar efter produktion. Vilka som är ”fungerande” beror helt på var företaget i fråga sätter ribban och vilka mål som har satts. Vilken spänning får användas för att nå upp till målen om total strömförbrukning och energieffektivitet i relation till prestanda (klockfrekvens). Det blir en binning-process där de bästa kretsarna plockas för det som i slutändan blir de bästa processorerna, medan kretsar av lägre kvalitet används i lägre segment. De sämsta kretsarna som kräver orimligt hög spänning i förhållande till klockfrekvens eller som är rentav trasiga kasseras.
Även efter binning finns variationer hos de många miljarder transistorer som utgör en krets. Det Precision Boost 2 gör är att genom hundratals sensorer välja de bästa kärnorna, det vill säga de som klarar högst klockfrekvens i förhållande till spänning, och prioritera dessa vid användning. Det sker i en intervall om 1 millisekund (0,001 sekunder) vilket motsvarar när en processor som körs i 4,0 GHz (4 000 000 000 klockcykler per sekund) hunnit med 4 miljoner (4 000 000) cykler. En evighet för en processor, men det AMD åstadkommit med Precision Boost 2 är fortfarande en av de snabbaste teknikerna på marknaden för att dynamiskt reglera en processors klockfrekvens.



En av de större nyheterna hos arkitekturen Zen 4 är stöd för instruktioner enligt AVX-512, som Intel under många år haft i utvalda processorer och som ökar prestandan rejält vid vissa flyttalsoperationer. Intel har i sina processorer en bred 512-bitars flyttalsenhet för att exekvera AVX-512-instruktioner på en klockcykel, vilket för med sig skyhög strömförbrukning och värmeutveckling med låga klockfrekvenser som följd.
När AMD till slut omfamnar ”Intels instruktion” utökar de inte storleken på flyttalsenheten, som stannar kvar vid en bredd om 256 bitar. I praktiken innebär detta att flyttalsenheten ”dubbelpumpas” (eng. double-pump) och att en instruktion utförs över två klockcykler, det vill säga över dubbelt så lång tid vid samma klockfrekvens. Det är en nackdel, som till viss del vägs upp av att strömförbrukningen och värmeutvecklingen inte sticker iväg och tvingar ned klockfrekvenserna på samma sätt som hos Intels processorer. Beslutet innebär även att kretsytan och därmed kostnaden blir lägre, då en 512-bitars flyttalsenhet är en stor tingest som kräver många transistorer.

